Analityka internetowa od zawsze narażona była na stały błąd pomiaru związany z działaniem adblocków oraz innych ograniczeń śledzenia. Mimo to odsetek utraconych danych był na tyle mały, że cały czas były one wiarygodne, istotne statystycznie i pozwalały podejmować właściwe decyzje biznesowe.
Adam Brzostek
20.04.2026Czas czytania: 15:00
Consent Exception Tracking - zrozum i wdróż to samodzielnie
Od 2024, kiedy w życie weszła ustawa Digital Service Act wymuszająca na właścicielach stron internetowych uzyskiwania zgody na śledzenie z wykorzystaniem identyfikatorów po stronie klienta, praca z danymi stała się naprawdę trudna. Czasem duży procent odrzuceń zgód w połączeniu z niejasnymi algorytmami Google Analytics sprawia, że wiarygodna statystyka jest w zasadzie niemożliwa.
Czy oznacza to, że nie mamy innego wyjścia i musimy podejmować decyzje tylko w oparciu o wątpliwej jakości trendy?
Nie do końca.
Czym jest consent exception tracking?
Consent exception tracking jest to specjalny model, który pozwala na śledzenie analityczne bez zgody. W założeniu tego modelu zbieramy w pełni zanonimizowane dane, które nie pozwalają w żaden sposób zidentyfikować użytkownika, a służą tylko statystyce.
Aby móc stosować ten model będąc w zgodzie z GDPR musimy spełniać kilka kluczowych warunków wejściowych:
- Pełna anonimizacja IP - adres IP musi być zredukowany od razu po odebraniu jakiegokolwiek żądania
- Brak fingerprintingu - nie pobieramy jakichkolwiek danych o urządzeniu pozwalających na jego identyfikację
- Brak cross-site trackingu - nie można śledzić użytkownika w witrynach 3rd party
- Brak eksportu danych - dane mogą być wykorzystywane tylko na własny użytek, nie można udostępniać ich jako żadnym podmiotom 3rd party, np. platformom marketingowym jak Google czy Meta.
Oznacza to, że dzięki śledzeniu consent exception tracking możemy zbierać informacje o wszystkich interakcjach, które wydarzyły się u nas na stronie. Niestety całkowicie rezygnujemy z analizy w zakresie użytkownika, w tym w określeniu czy jest to użytkownik nowy czy powracający.
Jakie informacje uzyskam dzięki Consent Exception tracking?
Poza informacjami o zdarzeniach model ten zezwala na krótkotrwałe identyfikatory sesyjne pozwalające na grupowanie zbieranych zdarzeń w ramach jednej wizyty, z zastrzeżeniem, że ich żywotność nie przekracza czasu jednej sesji.
Oznacza to, że to podejście pozwoli nam na zebranie informacji nie tylko o liczbie zdarzeń ale również o liczbie sesji oraz określić co podczas tych sesji się działo.
A co ze źródłami ruchu
Mamy kolejną dobrą informacje, ponieważ w tym modelu możemy zbierać informacje o źródłach ruchu, ale atrybucja działa tutaj tylko w ujęciu last click direct. Dzieje się tak, gdyż nie mamy dostępnego trwałego identyfikatora, który łączył by wizyty użytkownika w czasie, a więc możemy opierać się tylko na danych w obrębie sesji.
Z tego wynika też kolejna specyfika, która odróżnia tę atrybucje od last click, który znamy chociażby z Google Analytics - w consent exception tracking źródło direct zyskuje, bo w odróżnieniu od last click non-direct nie jest ignorowane przy kolejnej wizycie powracającego klienta.
W takim razie co z danymi urządzenia
Dane o urządzeniach znajdują się w nagłówku http o nazwie User-Agent. Możemy go pobrać, ale musimy zachować odpowiedni level ogólności, żeby czasem nie stworzyć fingerprintu użytkownika. Co za tym możemy wykorzystać:
| Wymiar danych | Czy możemy skorzystać | Uwagi |
|---|---|---|
| Typ urządzenia | TAK | Zobaczysz podział: Desktop, Mobile, Tablet, Smart TV. To dane o niskiej unikalności, więc są bezpieczne. |
| System operacyjny | TAK | Zobaczysz: Windows, Android, iOS, Linux. |
| Wersja systemu | Częściowo | Zamiast "Android 13.0.1" możesz widzieć tylko "Android 13" lub po prostu "Android". Zbyt dokładna wersja jest ryzykowna. |
| Przeglądarka | TAK | Zobaczysz: Chrome, Safari, Firefox. |
| Rozdzielczość ekranu | NIE / Ograniczone | W trybie ścisłej prywatności (np. konfiguracja CNIL w Piwik PRO/Matomo) ten parametr jest często usuwany lub zaokrąglany, ponieważ bardzo mocno identyfikuje konkretny model telefonu/monitora. |
| Marka/Model urządzenia | NIE / Ograniczone | Zamiast "Samsung Galaxy S22 Ultra" możesz widzieć ogólne "Samsung" lub "Android Device". |
Czyli nie będę miał żadnych informacji o użytkowniku?
Tutaj granica jest bardzo cienka ale po spełnieniu kilku warunków możemy zbierać user id.
Przede wszystkim obowiązują nas reguły przedstawione w pierwszym akapicie artykułu, czyli zbieranie User ID powinno służyć celom technicznym/bezpieczeństwa, a nie marketingowym.
Dla większego bezpieczeństwa warto user id zahashować przed zapisaniem go.
Po drugie - regulamin to podstawa. Jeżeli w regulaminie, akceptowanym podczas rejestracji, mamy zapisy informujące, że wykorzystamy dane do analizy zachowań wewnątrz witryny to uprawnia nas na przesyłanie user id bez zgody z CMP.
Jakie platformy oferują model consent exception tracking?
Consent exception tracking jest już oferowany przez popularne platformy analityczne.
Google Analytics
Przy odpowiedniej konfiguracji w GTM możemy powiedzieć, że Google Analytics w pewien sposób działa w tym modelu. Chodzi mi tu o konfigurację w oparciu o Advanced Consent Mode, kiedy to tagi GA4 uruchamiają się nawet bez udzielonej zgody i wysyłają do narzędzia pingi, czyli sygnały okrojone o pewne informacje, m.in client id czy session id. Jest to specyficzna forma consent exception tracking, ponieważ w panelu GA nie wyświetlamy danych rzeczywistych tylko dane modelowane. Więcej na ten temat znajdziemy w oficjalnej dokumentacji: https://support.google.com/analytics/answer/11161109?hl=pl
Piwik Pro
Inną platformą oferującą ten model zbierania danych jest Piwik Pro, posiadający dwie wersje takiego śledzenia:
- anonimowe śledzenie z Session Hash: nie używa ciasteczek, ale na podstawie zanonimizowanego adresu IP i User-Agenta (danych przeglądarki) generuje krótkożyjący hash sesji (np. na 30 minut). Pozwala to łączyć zdarzenia w pojedynczą wizytę, ale nie pozwala rozpoznać powracającego użytkownika następnego dnia.
- anonimowe śledzenie (No cookies, no session hash): to bohater tego artykułu. Piwik PRO nie zapisuje nic w przeglądarce i nie tworzy żadnego hasha łączącego zdarzenia. Każda odsłona, każde kliknięcie (ping) to dla serwera zupełnie niezależny, odizolowany byt.
Ten drugi model został już dokładnie opisany przez nas na blogu: https://bettersteps.pl/blog/zbieranie-danych-analitycznych-bez-zgody-uzytkownika-testuje-rozwiazanie-od-piwik-pro

Własny system
Ostatnim wariantem jest stworzenie własnego systemu. Można to zrobić w oparciu o server-side tracking oraz Google Big Query i taki wariant postaram się przybliżyć w tym artykule.
Jak wdrożyć consent exception tracking?
Nasz planowany system przedstawia się następująco. Z poziomu klienta będziemy wysyłać do sGTM dane za pomocą Stape Data tagu, a z sGTM dane będą przekazywane bezpośrednio do dedykowanej tabeli w Big Query za pomocą żądania typu http post obsługiwanego przez stworzoną instancję cloud run.
Ten artykuł przeczytasz tylko po zapisaniu się do newslettera
Dołącz do newslettera Bettersteps żeby zobaczyć pełną treść artykułu kompletnie za darmo
Zapisując się z tego formularza otrzymasz dostęp do całego materiału oraz na maila link do pobrania gotowych plików jSON dla GTM WEB oraz GTM SERVER, a także gotowe pliki do konfiguracji w Google Cloud
Przygotowanie Google GCP
Pierwszym krokiem jest przygotowanie naszego projektu Cloud do obsługi i gromadzenia przesyłanych ze strony żądań. W tym celu musimy utworzyć:
- Konto serwisowe do naszego systemu
- Dedykowaną tabelę w BQ o odpowiednim schemacie
- Instancję Cloud Run obsługującą żądania ze strony
Konto serwisowe
To najprostszy punkt całej zabawy - tworzymy zwykłe konto serwisowe i nadajemy mu uprawnienia Edytującego Dane Big Query - jest to konieczne, żeby konto w naszym imieniu mogło zapisywać dane do tabeli.
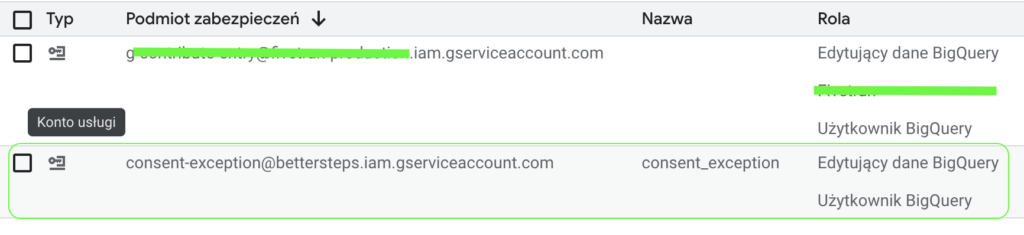
Tabela w BQ
W wybranym zbiorze danych tworzymy tabelę używając opcji Pusta tabela i wybierając deklaracje schematu za pomocą edytora tekstowego:
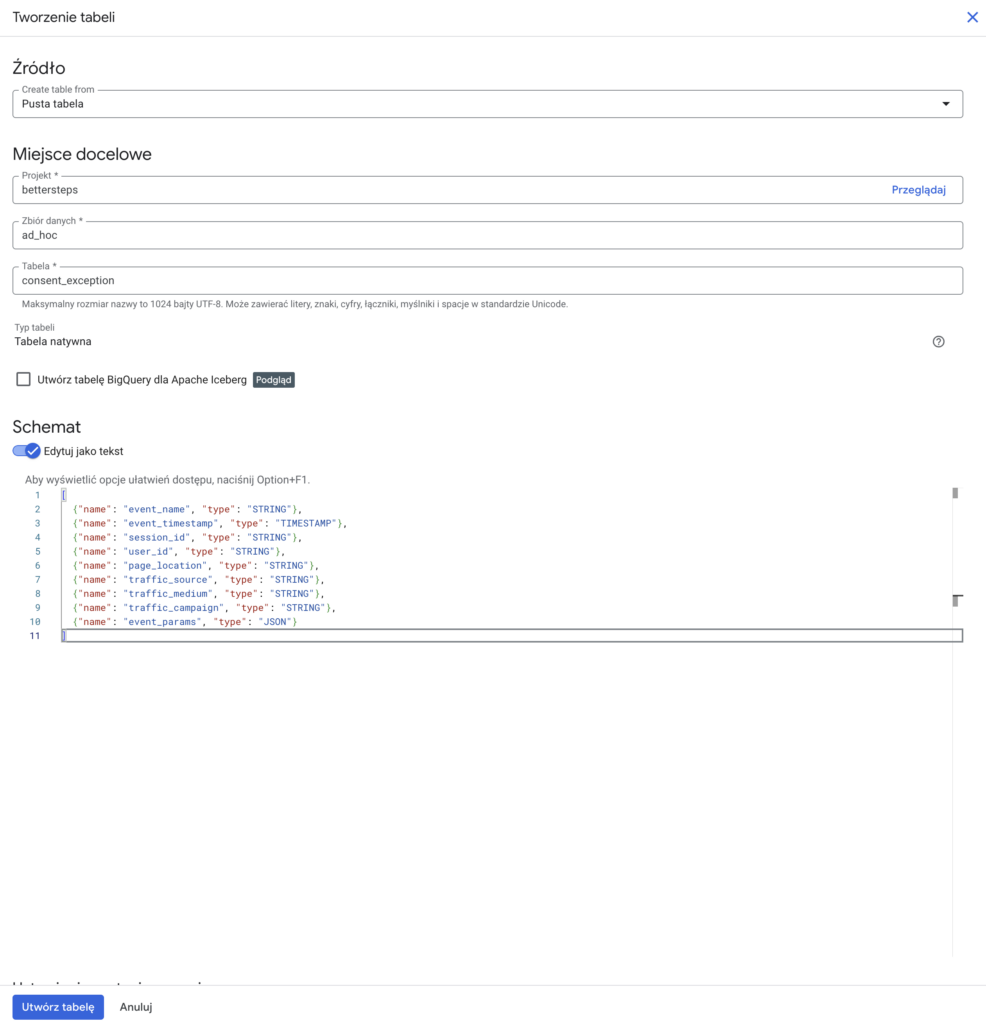
Schemat:
[
{"name": "event_name", "type": "STRING"},
{"name": "event_timestamp", "type": "TIMESTAMP"},
{"name": "session_id", "type": "STRING"},
{"name": "user_id", "type": "STRING"},
{"name": "page_location", "type": "STRING"},
{"name": "traffic_source", "type": "STRING"},
{"name": "traffic_medium", "type": "STRING"},
{"name": "traffic_campaign", "type": "STRING"},
{"name": "event_params", "type": "JSON"}
]Cloud run
Teraz przechodzimy do najbardziej skomplikowanej części zadania, czyli utworzenia dedykowanej instancji Cloud Run.
Włączenie API
Na początku musimy się upewnić, że wszystkie potrzebne API są włączone
- Cloud Run - deployment i hosting serwisu
- Cloud Build - budowanie obrazu Dockera
- Container Registry (albo Artifact Registry) - przechowywanie obrazu
- BigQuery - zapis danych do tabeli
- IAM - role, service accounts, permissions
- Service Usage - umożliwia włączanie innych API
- Cloud Logging - logi Cloud Run (debugowanie)
- Cloud Storage - używane przez Cloud Build (bucket na buildy)
Możemy to też zrobić jedną komendą w konsoli Cloud Shell
- Otwórz w Google Cloud: Cloud Shell (ikonka >_ w prawym górnym rogu konsoli).
- W Cloud Shell wklejamy poniższe polecenie i klikamy enter:
gcloud services enable \
run.googleapis.com \
cloudbuild.googleapis.com \
containerregistry.googleapis.com \
bigquery.googleapis.com \
iam.googleapis.com \
serviceusage.googleapis.com \
logging.googleapis.com \
storage.googleapis.comUtworzenie pliku index.js
Teraz musimy lokalnie utworzyć plik index.js, który będzie zbiorem instrukcji dla naszego systemu - w skrócie jest to kod z zestawem komend, które mówią jak nasz Cloud Run ma obsługiwać przychodzące ze strony żądania, tj. zapisać je do naszej tabeli w BQ
W dowolnym folderze stwórz plik tekstowy o nazwie index.js i wklej do niego poniższy kod:
const express = require('express');
const bodyParser = require('body-parser');
const { BigQuery } = require('@google-cloud/bigquery');
const app = express();
app.use(bodyParser.json({ limit: '1mb' }));
const bigquery = new BigQuery();
const DATASET = '<nazwa Twojego datasetu>';
const TABLE = '<nazwa Twojej tabeli>';
app.post('/', async (req, res) => {
try {
const e = req.body;
if (!e.event_name || !e.session_id || !e.page_location) {
return res.status(400).json({ error: 'Missing required fields' });
}
let eventParams = {};
if (e.event_params) {
if (typeof e.event_params === 'object') {
eventParams = e.event_params;
} else if (typeof e.event_params === 'string') {
try {
eventParams = JSON.parse(e.event_params);
} catch {
eventParams = {};
}
}
}
const row = {
event_name: String(e.event_name),
event_timestamp: e.event_timestamp
? new Date(e.event_timestamp)
: new Date(),
session_id: String(e.session_id),
user_id: e.user_id ? String(e.user_id) : null,
page_location: String(e.page_location),
traffic_source: e.traffic_source ? String(e.traffic_source) : null,
traffic_medium: e.traffic_medium ? String(e.traffic_medium) : null,
traffic_campaign: e.traffic_campaign ? String(e.traffic_campaign) : null,
event_params: JSON.stringify(eventParams)
};
await bigquery
.dataset(DATASET)
.table(TABLE)
.insert([row]);
res.status(200).json({ status: 'Inserted' });
} catch (err) {
console.error('BigQuery insert failed:', err);
res.status(500).json({ error: 'BigQuery insert failed' });
}
});
const PORT = process.env.PORT || 8080;
app.listen(PORT, () => {
console.log(`Server listening on port ${PORT}`);
});Nie zapomnij w pliku podmienić nazwy zbioru danych i tabeli
Stworzenie Cloud Run
W Cloud Shell utwórz folder projektu za pomocą poniższych komend:
mkdir cloudrun-bq
cd cloudrun-bqNastępnie zainstaluj BQ body parser
npm init -y
npm install @google-cloud/bigquery express body-parserTeraz musimy wgrać nasz plik index.js do naszego katalogu
- Kliknij ikonę Upload (strzałka w górę) w Cloud Shell
- Wybierz nasz plik index.js
- Czekamy aż upload się zakończy
Utworzenie Dockerfile
W terminalu w folderze cloudrun-bq stwórz plik Dockerfile:
touch DockerfileOtwórz go w edytorze nano:
nano DockerfileWklej do niego poniższy kod:
FROM node:18-slim
WORKDIR /app
COPY package*.json ./
RUN npm ci --omit=dev
COPY . .
ENV PORT=8080
CMD ["node", "index.js"]Zapisz zmiany → Ctrl + O, Enter
Wyjdź z nano → Ctrl + X
Zbuduj obraz dockera
gcloud builds submit --tag gcr.io/bettersteps/cloudrun-bqUtwórz kontener Cloud Run
Opuszczamy nasz edytor tekstowy Cloud Shell i utworzymy manualnie kontener Cloud Run
Zanim do tego przejdziemy to zachęcam do zapoznania się z artykułem na temat pułapek Cloud Run: https://bettersteps.pl/blog/pulapki-konfiguracji-gtm-server-side-w-technologii-google-cloud-run
A jeśli mamy to już za sobą możemy przejść do konfiguracji.
Otwórz w GCP Funkcje Cloud Run w Twoim projekcie

W panelu z lewego menu nawigacji przejdź do Usługi i Kliknij „Wdróż kontener”

W polu Adres URL obrazu kontenera podaj adres obrazu, który zbudowałeś w Cloud Build, np.:
gcr.io/bettersteps/cloudrun-bqW polu Nazwa zasobu Usługa podaj dowolną nazwę swojego kontenera
Jako region wybierz: europe-west
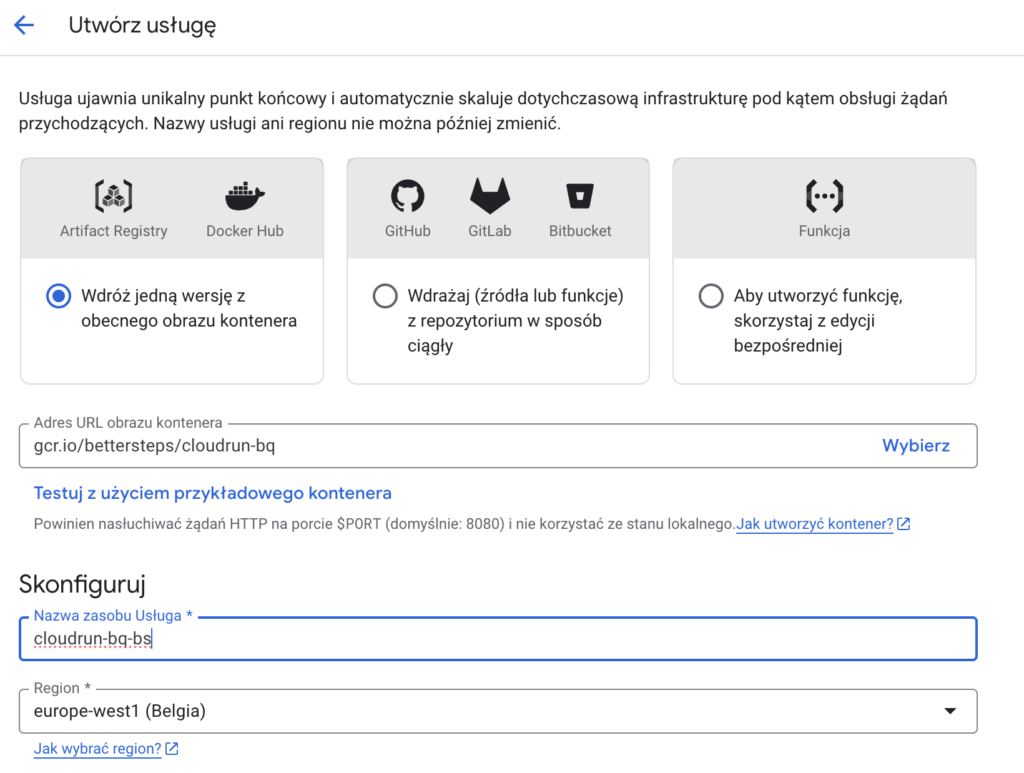
W sekcji Uwierzytelnianie zezwól na dostęp publiczny.
Wybierz płatność na podstawie żądań.
Zostaw opcje autoskalowania od zera.
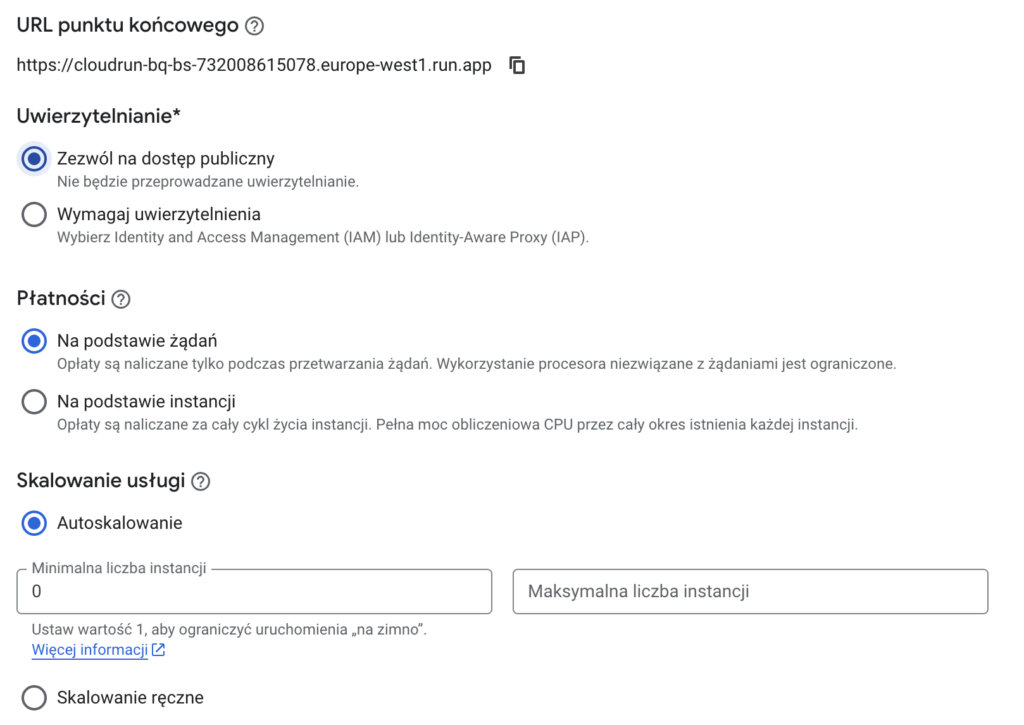
Ostatnim elementem do zmiany jest wybór konta serwisowego w sekcji zabezpieczenia na to, które utworzyliśmy wcześniej i które ma dostęp do BQ - to on będzie tam zapisywać dane.

Kliknij Utwórz i poczekaj kilka chwil, aż Cloud Run utworzy serwis.
Po zakończeniu deploy’u Cloud Run wyświetli URL serwisu.

To będzie Twój endpoint, który użyjemy w sGTM do wysyłki zdarzeń.
Wysłanie danych do sGTM
Istnieje wiele metod wysyłki danych do sGTM. Najprostszą i najbardziej powszechną jest używanie tagów GA4. Z racji tego, że chcemy aby nasz proces był całkowicie cookieless to ta metoda nie będzie dla nas odpowiednia.
My wykorzystamy Stape Data Tag.

Jest to gotowy szablon od Stape, dzięki, któremu łatwo możemy skonfigurować żądanie typu http post wysyłane do naszego serwera.
Za nim skonfigurujemy nasz tag musimy stworzyć zmienne opisujące nasz ruchu.
Pseudo session id
Ze wstępu wiemy, że model consent exception tracking zezwala na krótkotrwałe identyfikatory sesyjne działające w obrębie jednej sesji. Taki identyfikator będzie nam potrzebny, żeby łączyć zdarzenia z tej samej wizyty.
W naszym kontenerze GTM musimy utworzyć odpowiednią zmienną niestandardową, która utworzy taki unikalny identyfikator i zapisze go w session storage, żeby po zamknięciu przeglądarki wygasł.
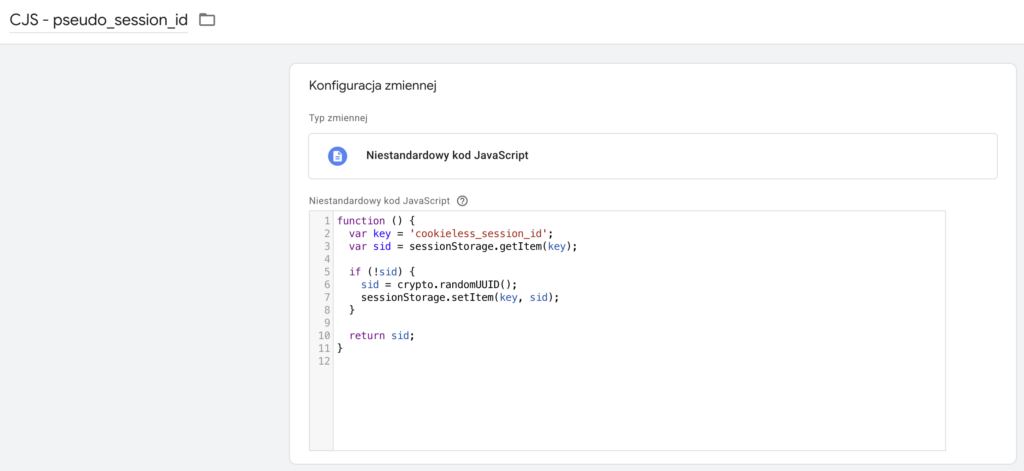
Źródła ruchu
W pliku JSON dla webowego kontenra GTM dołączonego do tego materiału znajdziesz niestandardowy tag HTML z kodem przechwytującym źródła ruchu w obrębie sesji i zapisującym ich wartość do session storage podobnie jak w przypadku pseudo session id.
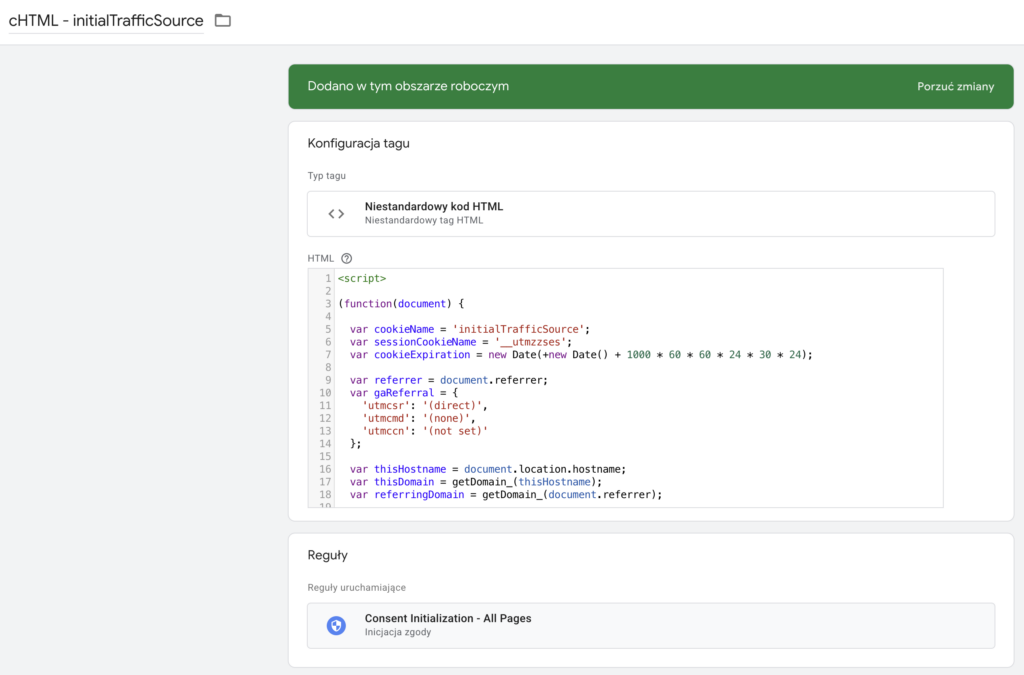
Działanie tego tagu jest dokładnie opisane na naszym blogu: https://bettersteps.pl/blog/atrybucja-danych-w-google-analytics-4-uszczelnij-sledzenie-na-swojej-usludze
Ten kod jest delikatnie zmodyfikowany i w pamięci sesyjnej zapisuje informacje o aktualnym:
- źródle - traffic_source
- medium - traffic_medium
- kampanii - traffic_campaign
Żeby pobrać te informacje i móc przesłać je do serwera musimy utworzyć 3 analogiczne niestandardowe zmienne java script jak na przykładzie:
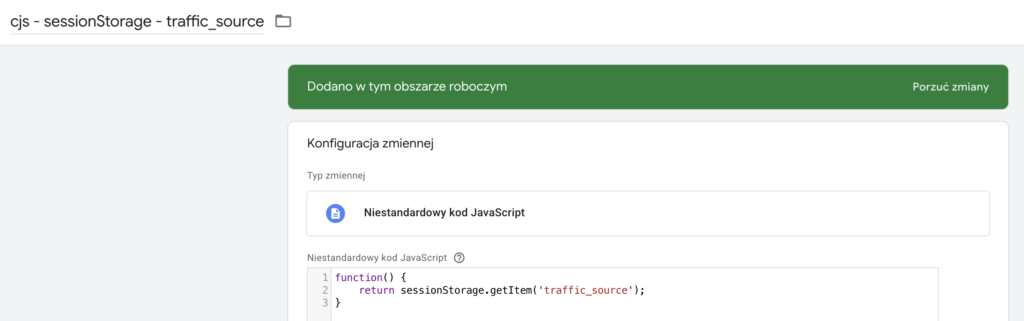
Konfiguracja Stape Data Tag
Mając już wszystkie potrzebne zmienne opisujące nasz ruchu możemy skonfigurować nasz Stape Data Tag.
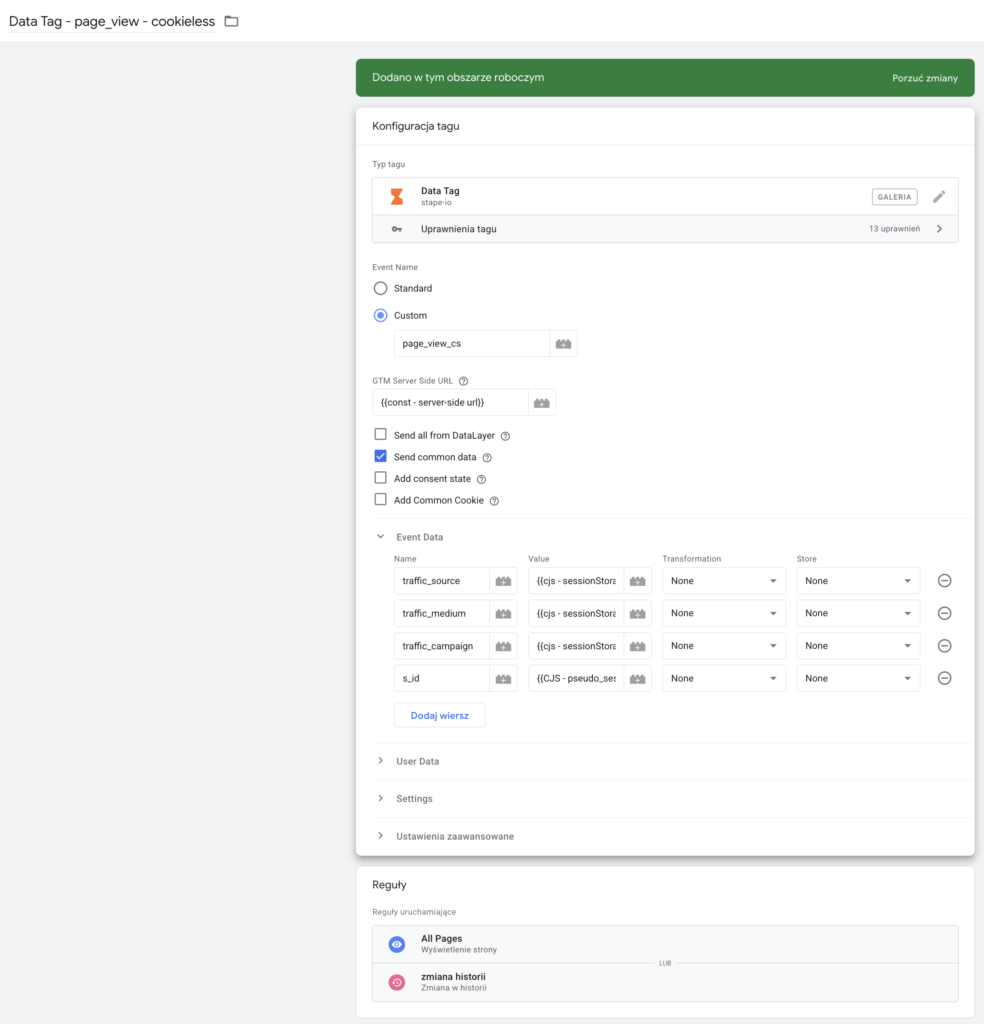
Jak typ zdarzenia wybierzmy Custom, żeby zadeklarować własne unikalne zdarzenie, które nie będzie wykorzystywane przez inne tagi w sGTM. W przykładzie chcę wysłać zdarzenie wyświetlenia strony, ale dodaje na końcu flagę “_cs”, żeby wiedzieć, że to zdarzenie cookieless.
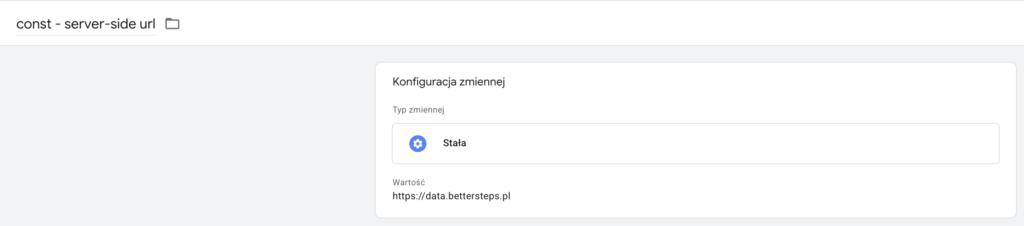
Muszę zadeklarować adres url mojego server tagowania przechowywany w zmiennej const - server-side url.
Zaznaczam checkbox Send common data, żeby odebrać standardowe parametry adresu url:
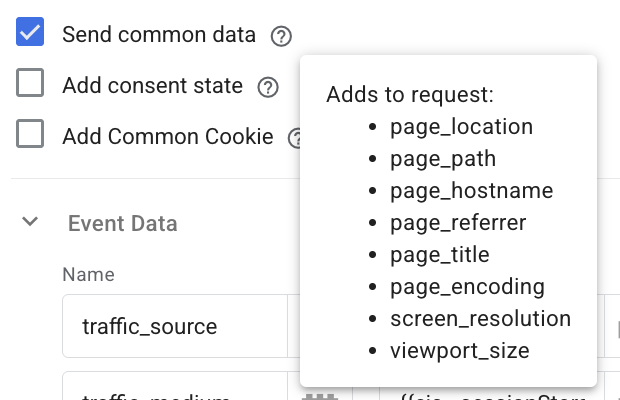
A następnie deklaruję moje parametry niestandardowe, czyli źródła ruchu oraz nietrwały identyfikator sesji - s_id.
Do tagu dodałem reguły uruchamiające się przy odsłonie nowej strony i w ten sposób skonfigurowałem wysyłanie informacji o wyświetleniach do mojego serwera tagowania.
Obsługa przychodzących żądań w sGTM
Stape Data Client
Żeby odebrać żądania wysyłane przez Stape Data Tag musimy w naszym kontenerze serwerowym skonfigurować Stape Data Client. Póki co nie ma galerii szablonów dla niestandardowych klientów sGTM, więc najnowszą wersje szablonu najlepiej pobrać z oficjalnego profilu Stape na Github: https://github.com/stape-io/data-client
Instrukcje jak go zainstalować znajdziemy tutaj: https://stape.io/blog/sending-data-from-google-tag-manager-web-container-to-the-server-container#how-to-send-data-from-the-google-tag-manager-web-to-the-server-container
Interesują nas punkty od 5 do 9 tej instrukcji.
Przesłanie zdarzenia do Big Query
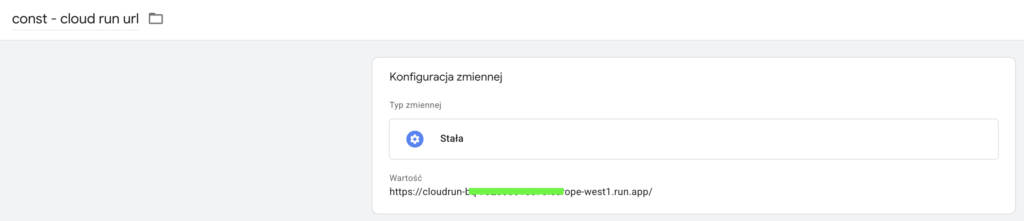
Dla ułatwienia na początek tworzymy zmienną przechowującą adres utworzonej przez nas wcześniej instancji Cloud Run.
Następnie tworzymy tag typu Żądanie HTTP.
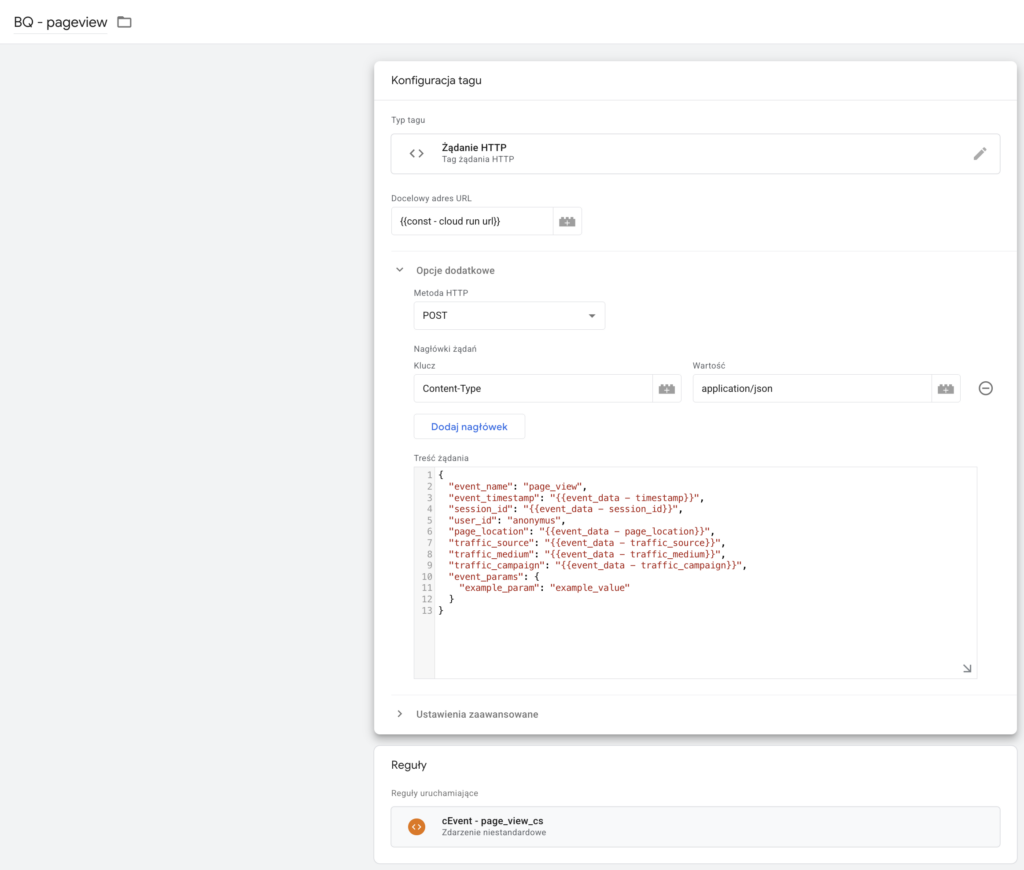
Deklarujemy tam adres naszego Cloud Run przechowywany we wcześniej utworzonej zmiennej const - cloud run url.
Wybieramy metodę POST
Jako klucz ustawiamy Content-Type z wartością application/json.
W treści żądania deklarujemy JSON zgodny z utworzoną przez nas tabelą w BQ oraz zadeklarowanym formatem w pliku index.js
W wartościach parametrów używamy zmiennych, które przechwytują informacje przesyłane ze strony, np:
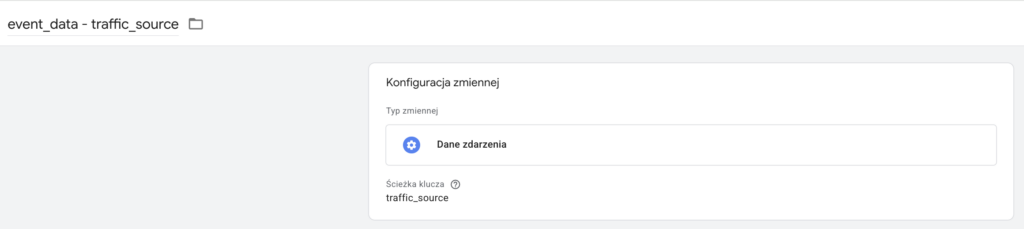
Jako regułę uruchamiającą musimy wybrać zdarzenie, które zadeklarowaliśmy przy wysyłce ze strony, np:
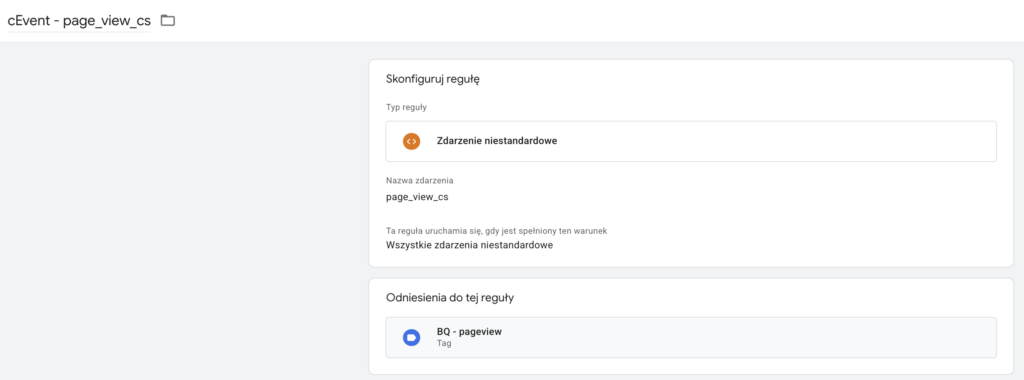
W debug view nasze żądanie powinno mieć status 200 - oznacza to, że przesłało się prawidłowo do naszej tabeli w BQ:
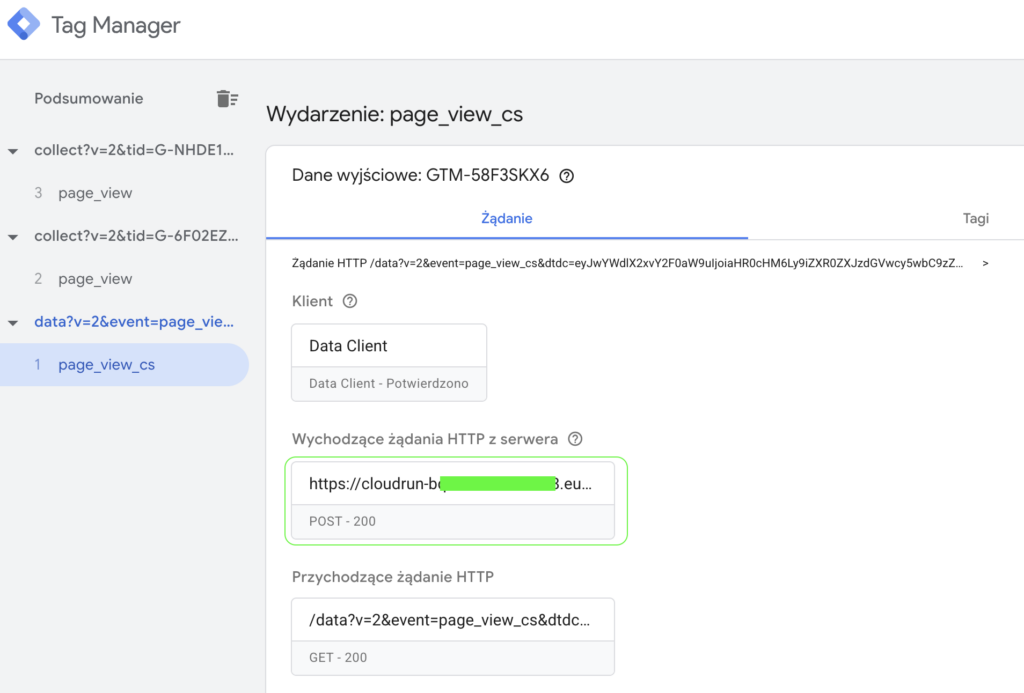
W podglądzie tagu powinniśmy w prosty sposób zobaczyć jakie dane są wysyłane:
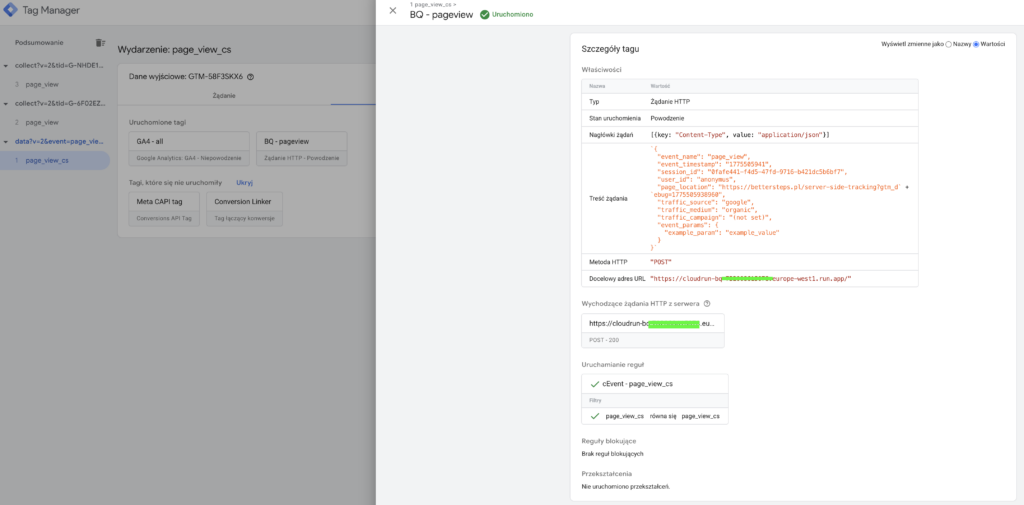
Jeżeli żądanie ma inny status niż 200 powinniśmy sprawdzić logi i wprowadzić wymagane zmiany. Może być to tylko zmiana formatu danych, żeby był zgodny z wymogami tabeli, ale może być też konieczne zaktualizowanie pliku index.js i ponowne wdrożenie instancji Cloud Run.
Na podstawie tego przewodnika wdrożyliśmy zdarzenie wyświetlenia strony, ale w analogiczny sposób możemy wdrożyć każde inne zdarzenie. Musimy pamiętać aby przestrzegać tylko wytycznych lokalnych organów prawa i zbierać tylko te informacje, które mają uzasadniony interes prawny.
Jak korzystać z plików JSON
Pliki zostały do obsługi zdarzenie wyświetlenia strony
Żeby model zadziałał konieczne jest wcześniej odpowiednie przygotowanie Google Cloud Platform, czyli:
- utworzenia tabeli Big Query
- Utworzenie odpowiedniej instancji cloud run
GTM client side
- Zaimportuj kontener
- Zaktualizuj zmienną const - server-side url
GTM server side
- Zaimportuj kontener
- Zaktualizuj zmienną const - cloud run url
Po pozytywnym debugu opublikuj obydwa kontenery
Zaobserwuj nasze profile, żeby nie przegapić innych ciekawych materiałów
